
Sunday, February 21, 2016
Monday, February 15, 2016
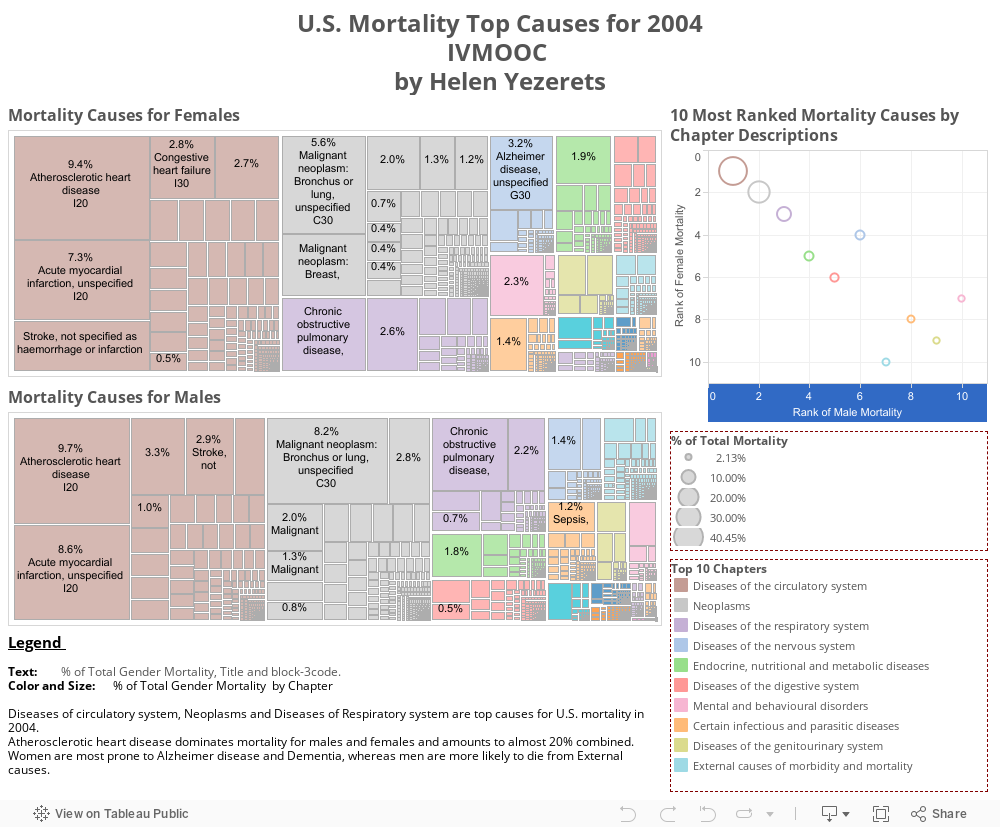
Wednesday, February 10, 2016
Data Visualization, Indiana University, IVMOOC Spring 2016
Word co-occurrence network visualization

Depicted the Web of Science-Computational linguistics from the period of 2011-2015 based on 743 journal articles. Among the most number of publications found are the following word roots: Languag, Model, Word, Recognit, Percept, Area, Brain, English, Sentenc and Memori. Nodes and edges sized and colorized proportionally to the number of the publications and connectedness between the nodes respectively. The strongest scientific interest is represented by the highest connectedness between Languag and Area/Percept tandem, as well as Langug-Word and Model-Word-Recognit units. At the same time, these word nodes represent the most number of publications ranging from 71 to 201 in 5 years.

Data Visualization, Indiana University, IVMOOC Spring 2016

The data was pre-processed in addition to the SC2 "Pre-processing" functionality as follows:
- removed 'auth' and 'transl' as unrelated to the mesothelioma research
- terms that were bursting in 1932 were reassigned to 1948 since the trends were current for 1948
- burst detection length was set to 1 to depict at least 2 years of burst
- the end date was set to 2010.
Subscribe to:
Comments (Atom)